Google ADK Voice Agents: What Works, What Breaks, and What’s Next
Table of Contents Expand
- 🟢 What Works Well (The Good)
- 1. Excellent Documentation & Quick Setup
- 2. The Smooth Transition from Text to Voice
- 3. On-The-Fly Accent Switching
- 4. Zero Pipeline Headaches
- 🔴 Where ADK Falls Short (Limitations)
- 1. The “Audio-Only” Blackbox
- 2. Inability to create a multi-agent system
- 3. Lack of instruction following
- 4. Unpredictable Event Yielding (The UI Headache)
- 🚀 The Alternative to ADK Voice: WebRTC
- 1. WebRTC over WebSockets
- 2. Separate STT and TTS Pipelines
- 3. Using ADK for What It Does Best
I love Google’s Agent Development Kit.
It’s a really powerful framework for building LLM-based text agents.
And recently, I also built a voice-agent using ADK. But I felt its voice capabilities are still a step behind.
In this post, I share my raw thoughts on ADK’s strengths and limitations with voice…
And what I believe is the best way to build a production-ready voice agent moving forward.
🟢 What Works Well (The Good)
Before I dive into the limitations, let me give credit where it is due.
There are a few things Google ADK does incredibly well when it comes to voice.
1. Excellent Documentation & Quick Setup
The ADK docs make it extremely easy to understand voice agents from first principles.
It clearly explains exactly what is happening under the hood:
- how events are yielded
- how the runner loop works
- how the
run_liveand therun_configtie everything together
You can follow the docs to quickly set up and test a basic agent locally (even without using ADK Web).
2. The Smooth Transition from Text to Voice
If you have already built text-only agents with ADK, moving to voice is almost frictionless.
The underlying architecture is nearly the same.
Both modalities use the exact same runtime loop. To adjust for voice, you only need a few minor tweaks.
For example: when building text agents, you use the runner.run_async function to create the event loop.
With audio, you simply replace that for runner.run_live to manage the live loop.
ADK makes the switch incredibly buttery smooth.
3. On-The-Fly Accent Switching
This feature actually blew my mind.
Because Gemini 3 Live is a native audio model, you can ask the agent to change its accent mid-conversation.
I tested this by asking the model to speak in a North Indian accent. It switched immediately… without needing any tweaks to the system prompt or backend configs.
And honestly, the accent quality was very good.
4. Zero Pipeline Headaches
Since Gemini has a live native audio model, building an agent is fast.
You don’t have to worry about stitching together separate speech-to-text (STT), LLM reasoning, and text-to-speech (TTS) pipelines. It is all handled natively out of the box.
But there is a catch.
While this “all-in-one” simplicity is great for quick builds… it’s also a bottleneck for advanced use cases.
And this brings me to its limitations…
🔴 Where ADK Falls Short (Limitations)
1. The “Audio-Only” Blackbox
Gemini 3 Live is purely audio-in and audio-out.
While it does transcribe the user input and the agent’s output (saving it to the ADK session service for history), you are locked into their native transcription model.
ADK does not let you use a custom STT model.
I feel this is a big limitation if you are dealing with heavy user accents or industry-specific terminology where a specialized STT provider would perform much better.
And, because it forces audio-only output, you also lose the flexibility to build hybrid workflows where a user could switch between voice vs text-only response.
2. Inability to create a multi-agent system
The ADK docs state that both the Gemini API and Vertex AI support the session resumption feature.
This feature is very important.
It allows you to pause and reconnect to a conversation.
And this feature is especially critical when building a team of sub-agents.
Because when the root agent has to transfer to a different agent, it needs to disconnect the live connection and resume on the sub-agent.
But here is the problem: I found that session resumption is actually not available on the Gemini API. It only works on Vertex AI.
Because of this, you just can’t build a multi-agent system using the Gemini API in voice mode.
3. Lack of instruction following
Compared to the text-only Gemini Flash models, the instruction-following of the Gemini 3 Live model is not as good.
Almost all Gemini models are really good at instruction following, even the 3.1 Flash Lite version.
But with the Live model, I had to revert to 2024-style prompt engineering. I had to explicitly repeat instructions at the top and bottom of the prompt to get it to properly follow the instructions.
4. Unpredictable Event Yielding (The UI Headache)
The way voice agents handle tool calls is different from text agents.
With text, the LLM yields events predictably.
But with the voice model, the agent can actually start responding to the user and make a tool call simultaneously while speaking.
Because of this, the order of events yielded by the runner loop is inconsistent. Sometimes it speaks first, sometimes it calls the tool first.
This unpredictability makes building a robust frontend UI a small headache.
🚀 The Alternative to ADK Voice: WebRTC
Voice-native models are good for simple tasks, but they still have catching up to do. Text models are simply far more powerful, robust, and predictable.
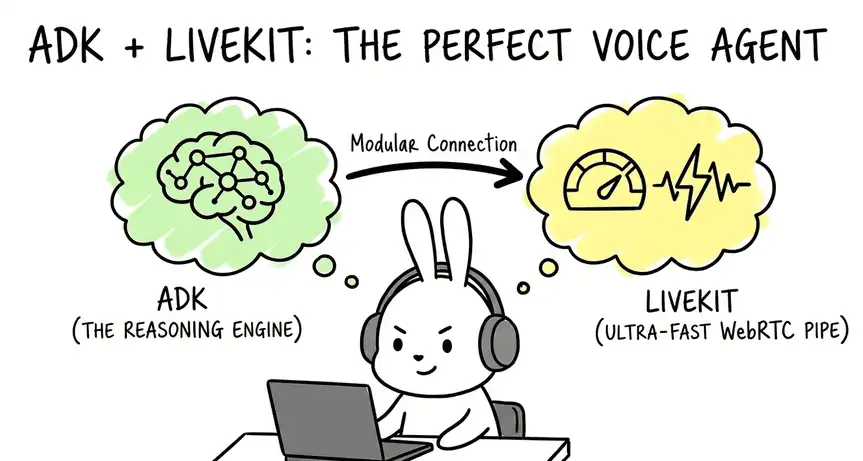
So, if I had to build a production-ready voice agent tomorrow, I wouldn’t use ADK for the audio layer at all.
Instead, I would build using LiveKit as the framework. And use Google ADK purely as the backend reasoning engine.
Here is why this modular approach is superior:
1. WebRTC over WebSockets
While ADK relies on websockets, LiveKit is built on WebRTC.
And when it comes to latency and speed, WebRTC is significantly faster, which is the secret to making a voice agent feel completely natural.
2. Separate STT and TTS Pipelines
Instead of relying on a black-box audio model, LiveKit allows you to build separate pipelines. You can easily replace one model for the other based on the business use case.
If I was building with LiveKit…
- For STT: I would use Soniox. Based on latency and pricing, I found their transcription accuracy to be better than Google, Deepgram and AssemblyAI.
- For TTS: I would use Google Cloud TTS or Grok’s new TTS model. Or perhaps one of the open-source alternatives.
3. Using ADK for What It Does Best
For the LLM part in LiveKit pipeline, I would actually use ADK.
And this is what would make this agent powerful.
ADK is one of the best frameworks out there. And by using it purely as the reasoning layer, this voice agent would have all the super-powers:
- The ability to build a team of sub-agents
- Rock-solid tool calling
- Easy session, memory and observability configuration
The “thinking” will be done entirely by a top LLM within the ADK framework…
while LiveKit would handle the ultra-fast audio transmission.
It sure sounds pretty interesting (actually mouthwatering if I’m being honest).
I hope to build this soon.
And once I do, I’ll share the code on GitHub and write a blog post about it.
If you agree, disagree, or are building something similar, I’d love to hear your thoughts. You can reach out to me directly on my email.